
How to make decisions based on data and experiments
And make them better
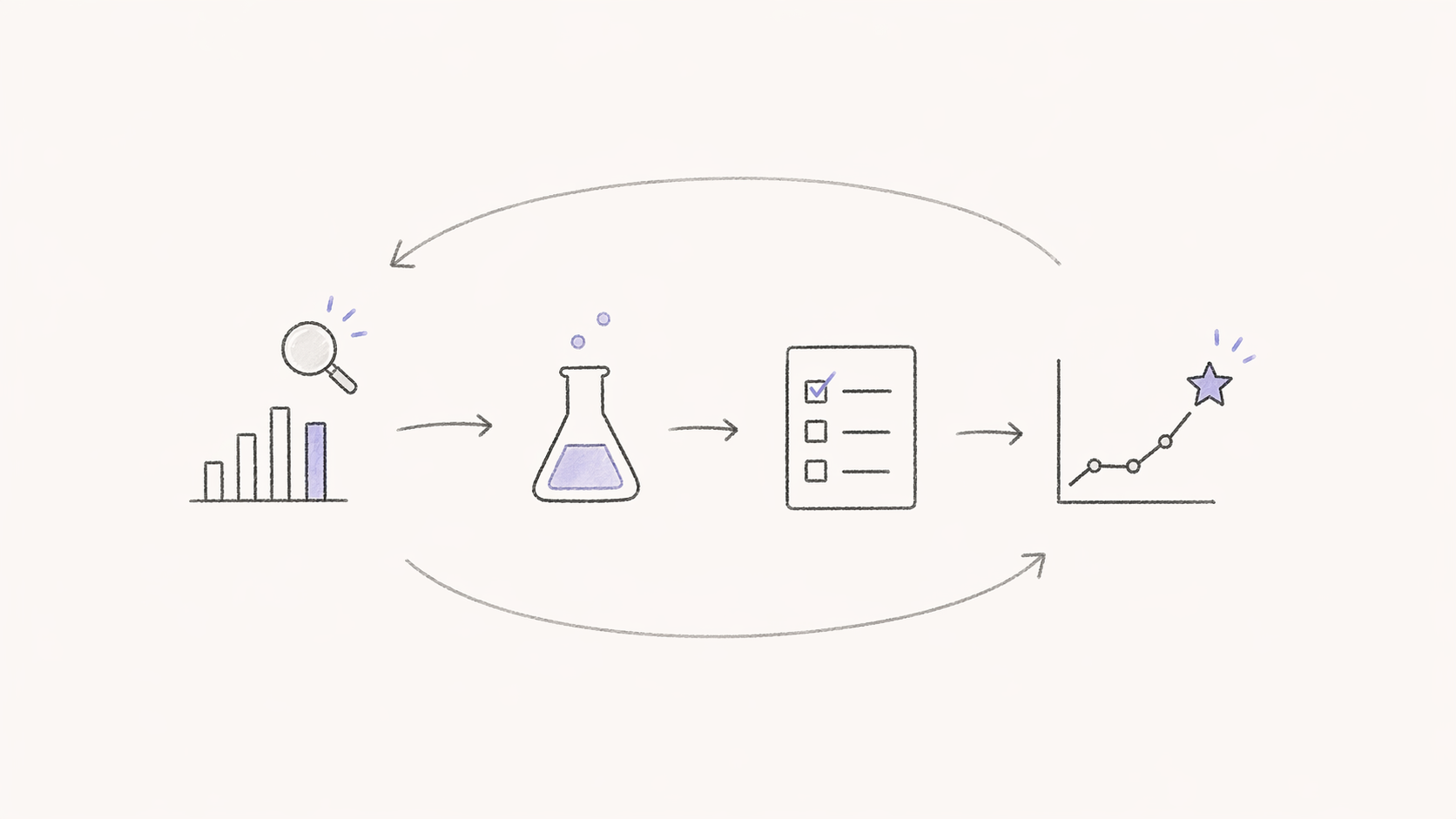
When I had my ICP-PDM certification training one of the topics, among others, was research and experimentation. Usually, when people talk about this part of product work, they talk about the types of research, its weaknesses and strengths, how to conduct it and how to get results. However, what is often left out is how the results are processed and interpreted. I think it is important to stress this point. After all, it is important not only to collect data and research results but also to make the right decisions based on them. If time is not taken to understand how to translate them into practical steps properly, serious mistakes can be made.
To reduce the risks of making decisions based on pure data, a knowledge management pyramid (DIKW - data-information-knowledge-wisdom) is usually used. It helps to improve the accuracy of your data, turning it into knowledge and wisdom. This is achieved through enrichment at each stage: first context is added, then meaning is enriched and finally understanding is added.
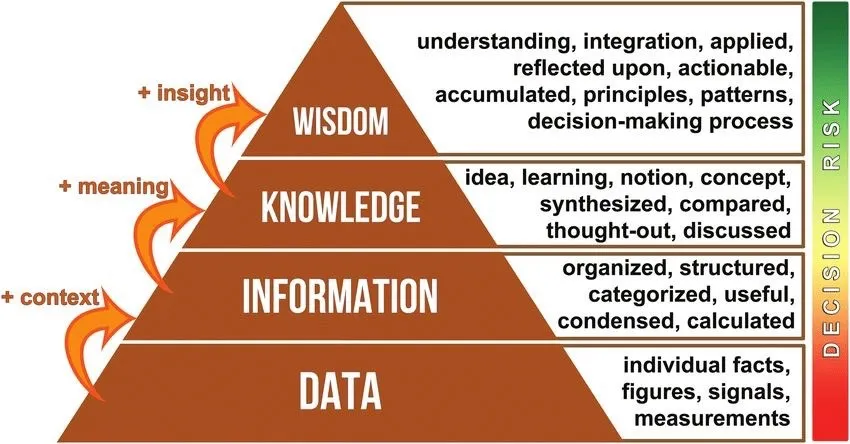
In fact, the higher up the pyramid your current understanding of information is, the lower the risk of making incorrect decisions based on that information.
It’s especially great that there are concepts that translate this into more practical terms. Daniel Pidcock has developed an excellent model - “The Atomic Research model”. It’s essentially based on the DIKW pyramid but shows in an applied way how to apply it all to real work. What is especially cool about this model is that it highlights how to link together information from multiple sources/research, reinforcing and amplifying the next level of the model. It looks like this (but I highly suggest reading his original article where he explains how he arrived at this model and goes into it in more detail):
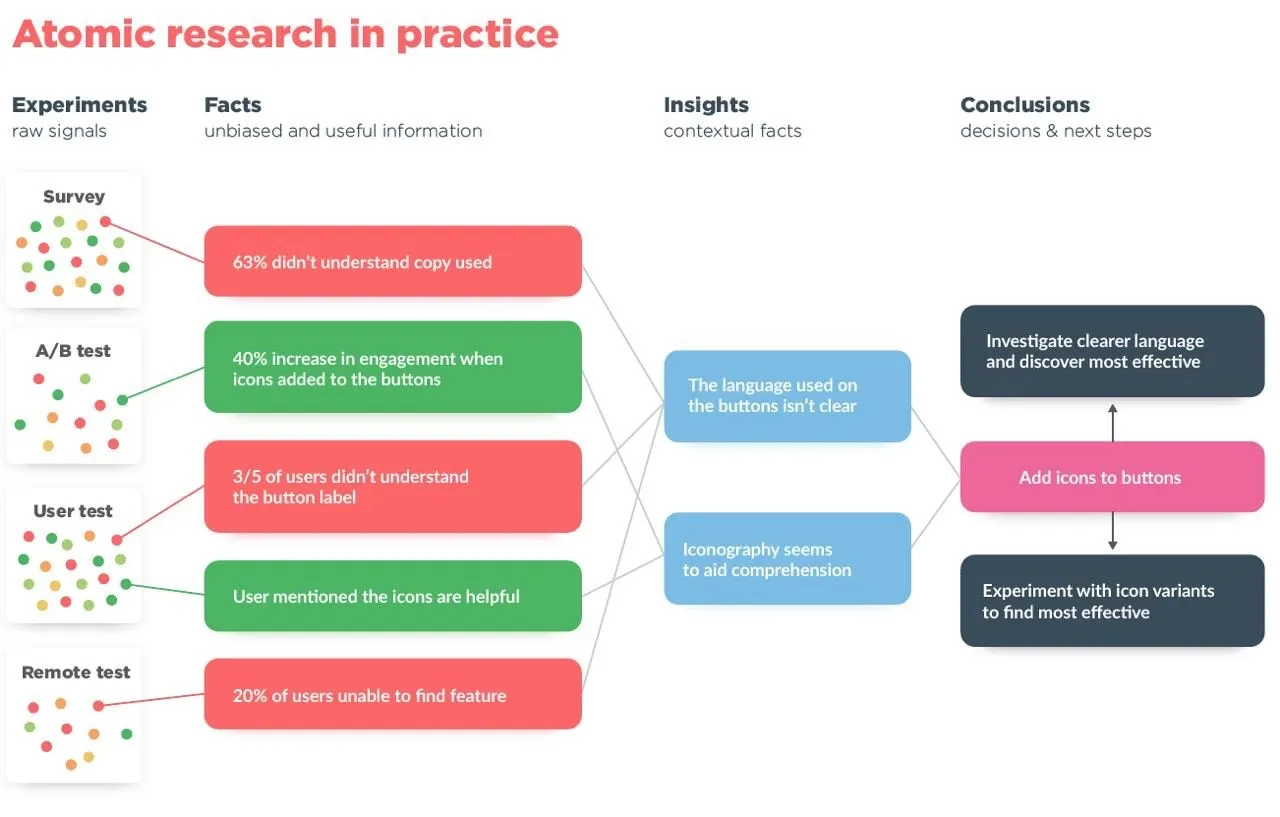
This model shows, among other things, how different types of research work in cooperation. In other words, following this model, the information from several separate experiments does not exist and is processed in isolation from other information about the product and users, but is intertwined in the process.
What remains to be understood is how to store all the accumulated information in a structured way without losing structure, connections and meanings. Daniel suggests a tool in his article, but to be honest I haven’t tried it yet.